
OAuth for AI memories
How AI memory sync could unlock a new era of personalized apps, without giving up control.


TL;DR – I propose an initial design for a secure layer that can extract users’ memories from LLM apps like ChatGPT and share them with third parties.
Here’s a demo video with a fully working implementation:
These days, I find myself interacting with lots of apps that have AI/LLM capabilities - and they all want to “know” me. For example:
Apollo.io wants to know what I’m working on and my writing style, so it can curate a list of leads and help me write email drafts.
Substack/Medium wants to know my favorite topics to build my feed.
AI therapists like Pi want to know about my past to better understand me.
And the list goes on. It feels like there’s a new wave of personalization happening. But this time, it feels a bit different. I’ll try to explain:
The old way: implicit vs explicit personalization
Up until recently, the main way apps personalized themselves to users was by slowly accumulating data over time. This data mostly fell into two categories:
Implicit data (a.k.a. behavioral data) - actions the user performs in the app (clicking on items, session duration in specific categories, liking certain things, etc.).
Explicit data (a.k.a. preference or declared data) - information users provide directly (selecting interests, giving ratings, setting profile preferences, filling surveys).
Once users “spent” enough time with a tool, it would start feeling more personalized.
However, this process is slow - and users have to invest time upfront, often without seeing huge value immediately.
Modern chatbots and memories
With the rise of popular chatbots - and the concept of memories - this dynamic might change. It seems we "share" a lot more with AI than we ever did with traditional apps. For instance:
I like to cook, and I often ask ChatGPT for advice:
how long to cook tomatoes for my pasta 🍝, whether I should close the lid when making lentil soup, or how to remove thyme stems from my tomato sauce.
After lots of conversations, I bet ChatGPT knows a thing or two about me when it comes to food and cooking. For example, it can probably tell that I love pasta and soups.
However, when I visit a recipe app to get ideas - or check out a cool cooking blog - there’s no way to reuse those memories.
I have to start from scratch every time and slowly re-teach those apps my preferences by using them more and more.
This led me to think: What if there was a secure layer of memories about me that apps could access - with my permission?
Think about it:
We spend a lot of time interacting with AI - whether it’s ChatGPT, Claude, Cursor, AI therapists, and more. However, the memories in those apps are siloed.
Companies hold the data - and it’s not easy (or even possible) for us, as users, to pull that information when we want.
What if we could allow apps to access our memories in a secure & scoped way that’d serve us across the internet?
I went deeper down that rabbit hole, and tried to draw inspiration from similar problems. Eventually, I realized that today we have a solution to a very similar problem. When one app wants to know something about a user in a secure, scoped way... OAuth comes to the rescue.
OAuth: A quick context refresher
In the early web days, there was a growing need for apps to interact with each other on behalf of users.
Around 2005–2010, the internet shifted from static websites to interactive web apps. Suddenly:
Users had data scattered across platforms (photos on Flickr, calendars & events on Google, contacts on Yahoo).
Developers started building applications that pulled data from multiple sources.
At that time, major platforms began opening APIs:
Facebook: Let apps post on your timeline.
Salesforce: Let apps pull leads, opportunities, account records.
Google: Let apps add events to your Calendar or read your Gmail receipts.
This created a new pattern:
“User logs into one app and wants it to take action on another app on their behalf.”
Allowing apps to do that meant users could enjoy a much better experience.
Instead of manually copying information between services, the app could simply integrate with your Google Calendar and set meetings for you automatically.
However, it introduced serious security problems.
Back then, if a developer wanted access to your Google account to integrate with your calendar, they had to ask you for your username and password.
By handing over your credentials, you were giving the app full access to your Google account - including Gmail, Drive, and everything else. They even had the ability to change your password.
And if that app ever got hacked, your password would be exposed in plain text!
OAuth was created to fix this:
it lets you grant apps scoped permissions to access only the data they need - without sharing your password.
For example, a travel app can ask Google for permission to view your calendar events, and Google will only share that specific data - without ever exposing your password to the app. You could also revoke it anytime, without changing your account’s credentials.
I won’t go into the full details of how OAuth works since it’s a massive topic. There are, however, great resources on this topic like this great blog post by Stack Auth that explains the basics. I highly recommend it!
OAuth for AI memories
So after I thought OAuth is interesting, it made me think:
What if there was an OAuth-like layer for AI memories?
A secure, scoped way for apps to access only the memories they need - with full user control.
Here’s a rough idea of how it could work:
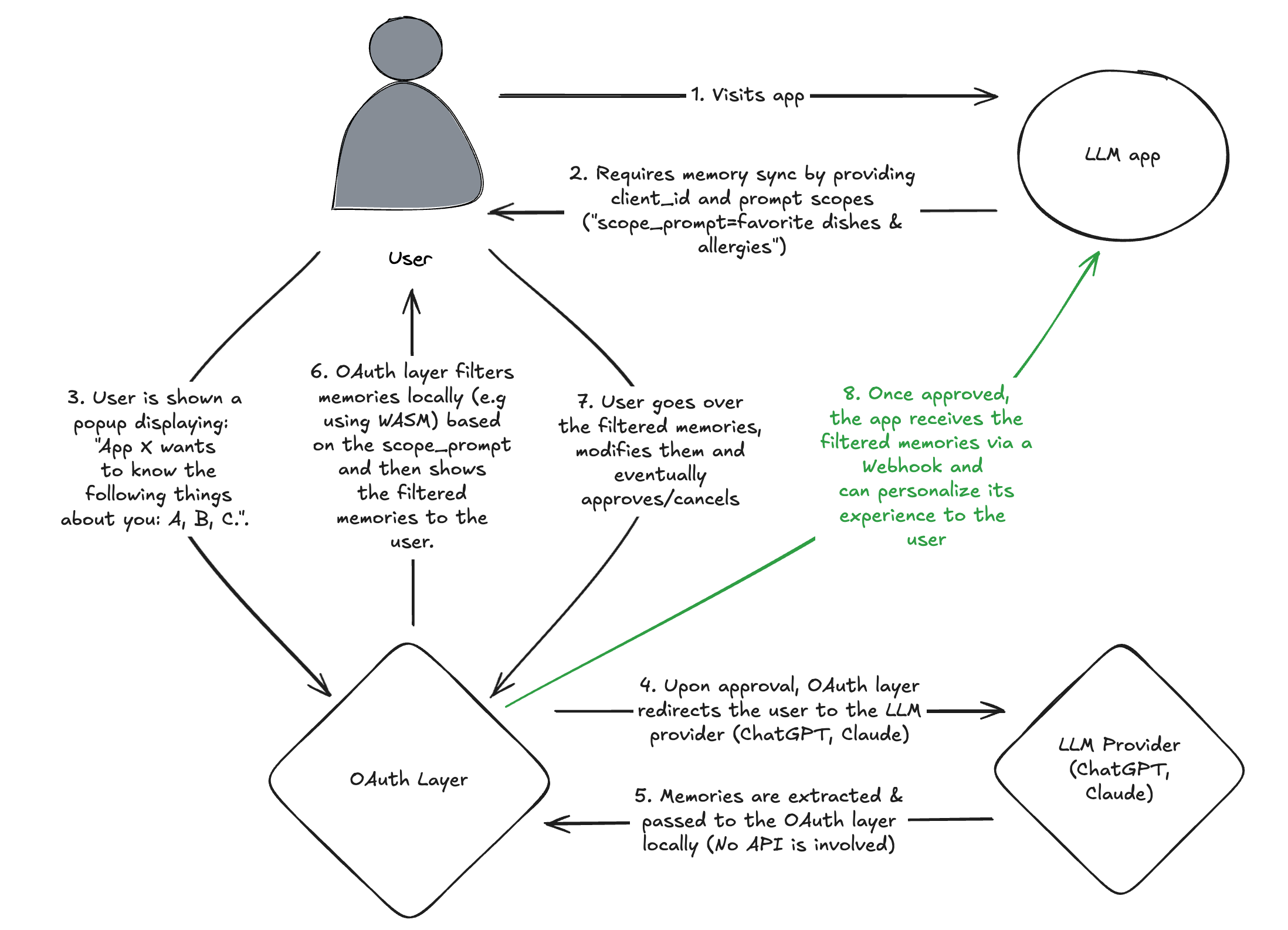
The flow would go like this (it’s also shown in the demo video above):
User enters an app that offers “memory sync” via a button.
User clicks and is redirected to the OAuth layer - a third-party service trusted with memory extraction & filtering (Think of it like the Google consent screen but for memories).
The app must pass:
client_id(who’s requesting)scope_prompt(what kind of memories it wants)redirect_url(where to send the filtered memories)llm_provider(which app to extract memories from e.g., ChatGPT, Claude)
User is shown a consent screen. They can see: which app is requesting memories (client_id is used) and what kind of memories it wants to retrieve (scope_prompt is used). The consent screen is shown in the demo above.
If consent is given, the user is redirected to the LLM provider (e.g., OpenAI, Anthropic). Before the redirect, the user is asked to add a bookmarklet (will explain next point why we need that).
User lands on LLM app and clicks the bookmarklet, which:
Crawls the memories
Encodes them in base64
Attaches them to the URL hash fragment (important: hash fragments aren’t sent to the server).
User is redirected back to our OAuth layer, which extracts & parses the encoded memories from the URL and runs a local LLM classifier (using Transformers.js, WebLLM, etc) that filters those memories based on the scope + pre-defined prompt. This model should be lightweight and should be downloaded & cached initially when we load the consent screen.
We run the inference locally because we don’t want to send the memories to a remote API. It’s a super sensitive information, hence it should be handled locally.Once memories are filtered, they are shown to the user for a final review before sharing. In the review phase, the user is able to discard memories or modify them. This is an important phase, since our LLM classifier might be wrong in certain cases and might include sensitive memories that are not relevant to the scope.
Once the memories are reviewed by the user, a final approval is given, making the OAuth layer send the memories to the application by sending an HTTP POST request to redirect_url.
This is the flow that you can see in the demo. I skipped some unimportant technical things, but in general I tried to apply the OAuth method to memories.
In theory & practice, it’s pretty cool. However, eventually I thought about some challenges that made me realize it might be too early.
Some important notes & challenges
There are a lot of flaws in this design, and some things remain unknown/unsolved. Here are some important notes & challenges that I think are important to talk about:
You might be thinking "Wait - shouldn’t OAuth be implemented by the LLM providers themselves?
Why would users trust a third-party OAuth layer? Isn’t that the point of OAuth?"👉 You’re right. Ideally, OpenAI, Anthropic, and Google should implement this themselves.
But I doubt they’ll offer something like this. Their incentives might not align with letting users easily export memories to 3rd party apps.Memories are inherently different than an “access token”. Originally, the purpose of OAuth was to grant revocable access to 3rd parties. Memories lack that property. Once memories are passed to a 3rd party, that’s it. There’s no way to make them “forget” that information.
As of 2025, LLM providers don’t know that much about us (a.k.a data is very sparse)
The memories they collect are often shallow or fragmented, making the immediate demand for memory-sharing relatively low. However, as people immerse deeper into AI interactions over time, I can see this changing dramatically.Keeping memories fresh is a must & major challenge. One day I might think my coworker is amazing; the next, I might be complaining about him. 😅
In this model (where the OAuth layer isn't directly managed by the LLM provider), keeping memories continuously updated (on the 3rd party side) would be very hard.
You could theoretically implement background listeners that evaluate new conversations in real-time and update relevant scopes - but you’d have to keep prompting the user for reviews, and that could get very tedious.In my demo, I didn’t implement full protections like CSRF safeguards, redirect URI validation, or other critical OAuth security practices.
These would absolutely need to be built in for a real production-ready system.Local inference is a must IMO (unless LLM providers themselves build this).
If a third-party OAuth layer handles memory extraction, inference must happen locally - directly in the user's browser - using tools like Transformers.js, WebLLM, etc. Managing that data on the server, even if it’s just for transit, might impose serious security risks. Memories are extremely sensitive, and sending them to a remote server would defeat the purpose of user-controlled privacy. It might also be illegal but I haven’t thought about that too deeply 🧐Modern browsers let you run arbitrary JavaScript through bookmarklets (which is super cool, didn’t know that 😊).
However, there are limits:CSP (Content Security Policies) on LLM sites like OpenAI restrict which external scripts can load. I tried injecting libraries like Transformers.js via CDN inside a bookmarklet, but it was blocked by OpenAI’s CSP.
To mitigate that, I tried bundling everything using Webpack into a single minified JS file, but bookmarklets have size limits (since it’s just a big string) - and eventually the browser collapsed under the weight. 😅
This means you can’t run very smart logic in the bookmarklet code. You have to either make the user install an extension (which is a big no-no IMO) or run just the simple logic and pass the data back to the main OAuth app.
So although it was a super fun weekend project, I think it’s indeed too early for this concept to fully materialize, due to these challenges.
Final thoughts
Those are my thoughts and notes for now. I hope you enjoyed this post.
While there are still major challenges that make this reality feel far away,
I do believe we’ll reach a day where we’ll interact with an AI friend - or even a dating app co-pilot - and be able to instantly share all the important things there are to know about us in a secure & scoped way. I think it can dramatically improve our productivity and maximize our digital experience 🚀